Django QuerySet
1. QuerySet
1.1. Query
A query is a request for data from a database.
1.1. What is QuerySet
A QuerySet represents a collection of objects from your database.
Github django.db.models.query QuerySet
QuerySet consists of one query and several query sets.
Therefore, QuerySet can be considered query.
The reason why QuerySet works like a collection of objects is because QuerySet caches data.
1.1.1. Check SQL Query
You can check the SQL query by checking query attribute of QuerySet
queryset = MyModel.objects.all()
print(queryset.query)
1.2. QuerySet API
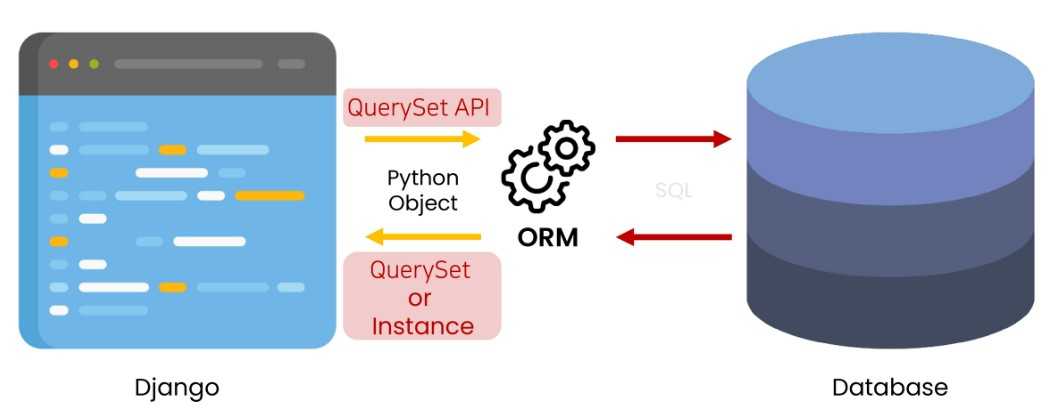
QuerySet API is the method that can make queries(QuerySet).
Once you’ve created your data models, Django automatically gives you a database-abstraction API that lets you create, retrieve, update and delete objects.
1.3. QuerySet Evaluation and Caching
1.3.1. Evaluation and Caching
When QuerySets are evaluated, queries actually hit the database, and the result is cached(saved) in self._result_cache.
Internally, a QuerySet can be constructed, filtered, sliced, and generally passed around without actually hitting the database. No database activity actually occurs until you do something to evaluate the queryset.
1.3.1. Lazy Loading
- Iteration
- A QuerySet is iterable, and it executes its database query the first time you iterate over it.
for e in Entry.objects.all(): print(e.headline)
- A QuerySet is iterable, and it executes its database query the first time you iterate over it.
-
Asynchronous iteration
-
A QuerySet can also be iterated over using async for:
async for e in Entry.objects.all(): results.append(e)
-
-
Slicing with Step
-
As explained in Limiting QuerySets, a QuerySet can be sliced, using Python’s array-slicing syntax. Slicing an unevaluated QuerySet usually returns another unevaluated QuerySet, but Django will execute the database query if you use the “step” parameter of slice syntax, and will return a list. Slicing a QuerySet that has been evaluated also returns a list.
-
Also note that even though slicing an unevaluated QuerySet returns another unevaluated QuerySet, modifying the returned unevalutaed QuerySet further (e.g., adding more filters, or modifying ordering) is not allowed, since that does not translate well into SQL and it would not have a clear meaning either.
-
-
Pickling
-
If you pickle a QuerySet, this will force all the results to be loaded into memory prior to pickling. Pickling is usually used as a precursor to caching and when the cached queryset is reloaded, you want the results to already be present and ready for use (reading from the database can take some time, defeating the purpose of caching). This means that when you unpickle a QuerySet, it contains the results at the moment it was pickled, rather than the results that are currently in the database.
-
If you only want to pickle the necessary information to recreate the QuerySet from the database at a later time, pickle the query attribute of the QuerySet.
import pickle query = pickle.loads(s) # Assuming 's' is the pickled string. qs = MyModel.objects.all() qs.query = query
-
-
repr()
- A QuerySet is evaluated when you call repr() on it. This is for convenience in the Python interactive interpreter, so you can immediately see your results when using the API interactively.
-
len()
- A QuerySet is evaluated when you call len() on it. This, as you might expect, returns the length of the result list.
- If you only need to determine the number of records in the set (and don’t need the actual objects), it’s much more efficient to use
QuerySet.count.
-
list()
- Force evaluation of a QuerySet by calling list() on it. For example:
-
bool()
- Testing a QuerySet in a boolean context, such as using bool(), or, and or an if statement, will cause the query to be executed. If there is at least one result, the QuerySet is True, otherwise False.
-
If you only want to determine if at least one result exists (and don’t need the actual objects), it’s more efficient to use exists().
if Entry.objects.filter(headline="Test").exists(): print("There is at least one Entry with the headline Test")
2. Basic CRUD
2.1. Model
from django.db import models
class User(models.Model):
first_name = models.CharField(max_length=15)
last_name = models.CharField(max_length=20)
age = models.IntegerField()
country = models.CharField(max_length=20)
phone = models.CharField(max_length=20)
balance = models.IntegerField()
2.2. Create
User.objects.create(first_name='Kim', last_name='Soo', ...)
2.3. Read
Read all the records
User.objects.all()
Read the 101th record
User.objects.get(pk=101)
2.3.1. values()
Returns a list of dictionaries which keys are the field name and the value is the data. It gets the field name you want to represent as parameters.
User.objects.values()
User.objects.values('name').filter(id__lt=8)
2.3.2. values_list()
Returns a list of tuples which elements are the data. It gets the field name you want to represent as parameters.
User.objects.values_list()
User.objects.values_list('name').filter(id__lt=8)
2.4. Update
Update the 101th record's last_name into 'Kim'
user = User.objects.get(pk=101)
user.last_name='Kim'
user.save()
2.5. Delete
Delete the 101the record
user = User.objects.get(pk-101)
user.delete()
2. Sort Data
order_by()
- Sort in ascending order, in the order of field names received as parameters.
- To sort in descending order, put '-'' before the field name.
- To sort in random, put '?' as a parameter.
- Read first_name and age in order of age
User.objects.order_by('age').values('first_name', 'age')
- Read all the fields in order of age
User.objects.order_by('age').values()
- Read first_name and age in reverse order of age
User.objects.order_by('-age').values('first_name', 'age')
- Read first_name and age in random order
User.objects.order_by('?').values('first_name', 'age')
- Read first_name in order of age. If the age is the same, sort in reverse ordef of account_balance
User.objects.order_by('age', '-balance').values('first_name')
3. Filter Data
distinct()
- Read all the countries without duplication
User.objects.distinct().values('country')
- Read all the countries without duplication inf order of country
User.objects.distinct().values('country').order_by('country')
gte, gt
- Read first_name with age == 30
User.obejcts.filter(age=30).values('first_name')
- Read first_name with age >= 30
User.obejcts.filter(age__gte=30).values('first_name')
- Read first_name with age >= 30 and balance > 50
User.obejcts.filter(age__gte=30, balance__gt=50).values('first_name')from django.db.models import QUser.objects.filter(Q(age__gte=30) & Q(balance__gt=50))
contains, startswith, endswith
- Read first_name which contains 'A'
User.obejcts.filter(first_name__contains='A').values('first_name')
- Read phone which starts with '011'
User.obejcts.filter(phone__startswiths='011-').values('phone')
- Read phone which endswith with '9'
User.obejcts.filter(phone__endswith='9').values('phone')
in
- Read first_name of people who live in Korea or America
User.obejcts.filter(country__in=['Korea, 'America'']).values('first_name')
- Read first_name of people who don't live in Korea or America
User.obejcts.exclude(country__in=['Korea, 'America'']).values('first_name')
slicing
-
Read first_name of the 10 yougest people
User.obejcts.order_by('age').values('first_name')[:10]
Q
- Read first_name of people 'whose age is 30' or 'whose the last_name is 'Kim''
-
from django.db.models import Q` User.objects.filter(Q(age=30) | Q(last_name='Kim'))
-
4. Group Data
4.1. Aggregation
from django.db.models import function_name
-
It returns a dictionary which key is
'ParameterName\_\_FunctionName'. The name of the key can be set.User.objects.filter(age__gte=30).aggregate(Avg('avg')) # {'age__avg': 36.25} User.objects.filter(age__gte=30).aggregate(average=Avg('avg')) # {'average': 36.25} -
Read the largest balance
User.objects.aggregate(Max('balance'))
-
Read the sum of balance
User.objects.aggregate(Sum('balance'))
4.2. Annotation
Add an additional columm for the records grouped by values()
- Read the number of people in each country
User.objects.values('country').annotate(Count('country'))
- Read the number of people and the average of balance in each country
User.objects.values('country').annotate(Count('country'), avg_balance=Avg('balance'))
4.2.1. Annotation In N:1
Example 1
-
The relationship between comments and articles is N:1.
# N : 1 = Comment : Article Article.objects.annotate( number_of_comment=Count('comment'), number_of_recent_comment=Count('comment', filter=Q(comment__created_at__lte='2000-01-01')) )- The parameter 'comment' is not related_name, but model_name
Example 2
-
models.py
class Question(models.Model): title = models.CharField(max_length=50) issue_a = models.CharField(max_length=50) issue_b = models.CharField(max_length=50) class Comment(models.Model): question = models.ForeignKey(Question, on_delete=models.CASCADE) content = models.CharField(max_length=100) pick = models.BooleanField() -
forms.py
class CommentForm(forms.ModelForm): PICK_A = False PICK_B = True PICKS = [ (PICK_A, '왼쪽'), (PICK_B, '오른쪽'), ] pick = forms.ChoiceField(choices=PICKS) class Meta: model = Comment fields = '__all__' -
views.py
def detail(request, question_pk): count_a = Count('comment', filter=Q(comment__pick=False)) count_b = Count('comment', filter=Q(comment__pick=True)) total_count = Count('comment') question = Question.objects.annotate( count_a = count_a, count_b = count_b, totla_count = total_count, ).get(pk=questioin_pk) question.count_a # 왼쪽을 선택한 코멘트 갯수 question.count_b # 오른을 선택한 코멘트 갯수
6. Query Optimization
References
Table Relations
- 1:N (Article-Comment)
- 1:N (User-Article)
- 1:N (User-Comment)
6.1. annotate
-
Display the number of comments for each article in the index_1.html
def index_1(request): articles = Article.objects.annotate(Count('comment')).order_by('-pk') context = { 'articles': articles, } return render(request, 'articles/index_1.html', context)
6.2. selected_related()
- select_related(*fields)
Make
INNER JOINquery for the field which is ForeignKey or OneToOneField relation.
-
Display the username for each article in the index_2.html
def index_2(request): articles = Article.objects.select_related('user').order_by('-pk') context = { 'articles': articles, } return render(request, 'articles/index_2.html', context)
6.3. prefetch_related()
- prefetch_related(*lookups) Make other QuerySets for the lookup which are ManytoManyField OneToMany dereference relation.
-
Display all the comments for each article in the index_3.html
def index_3(request): articles = Article.objects.prefetch_related('comment_set').order_by('-pk') context = { 'articles': articles, } return render(request, 'articles/index_3.html', context)
6.4. Prefetch()
- Prefetch(lookup, queryset=None, to_attr=None)¶
- The Prefetch() object can be used to control the operation of prefetch_related().
-
Display the author and all the comments for each article in the index_4.html
def index_4(request): articles = Article.objects.prefetch_related( Prefetch('comment_set', queryset=Comment.objects.select_related('user')) ).order_by('-pk') context = { 'articles': articles, } return render(request, 'articles/index_4.html', context)